
Auf Google+ kam kürzlich die Frage auf, ob und wie sich die sitemap.xml aus dem Suchmaschinen-Index heraus halten lässt. Eine site- oder inurl-Abfrage bei Google zeigt bei vielen Websites und Blogs, dass unter anderem die robots.txt, die sitemap.xml, PDF-Dokumente und eventuell weitere Dateien, die nicht für Suchmaschinen relevant sind, über die Suche gefunden werden können. Das ist normalerweise unproblematisch, aber überflüssig und oftmals nicht gewünscht.
Nun lassen sich die robots.txt, die sitemap.xml, readme.dat, PDF- oder Office-Dokumente nicht einfach per Meta-Robots-Anweisung auf noindex setzen. Diesen Metatag trifft man häufig in HTML-Seiten mit unterschiedlichen Attributen an. Er sorgt in der folgenden Konstellation dafür, dass diese Seite nicht indexiert wird – sie nicht über Suchmaschinen zu finden sein wird:
<meta name="robots" content="noindex" />
Auch ein Disallow: /sitemap.xml innerhalb der robots.txt macht keinen Sinn. Denn schließlich ist eine sitemap.xml für die Suchmaschinen-Crawler gedacht und sie sollen natürlich nicht vom Lesen dieser Datei ausgeschlossen werden. Des weiteren dient die robots.txt nicht zur Indexierungs-Steuerung von Webinhalten.
Wie lässt sich die sitemap.xml und die robots.txt aus dem Google-Index verbannen? Wie lässt sich eine Indexierung der eigenen Webinhalte durch die Suchmaschinen steuern? Wie lässt sich eine PDF-Datei bei Google ausschließen?
Noindex-Anweisung für die robots.txt
Um einen Response-Header mit der Anweisung „noindex“ für eine bestimmte Datei zu senden, genügt der folgende Eintrag innerhalb der .htaccess-Datei bzw. in der Apache- oder Virtualhost-Konfiguration. In diesem Beispiel wird bei einem Aufruf der robots.txt der X-Robots-Tag „noindex“ hinzugefügt. Den Suchmaschinen, die diesen Header unterstützen wird so mitgeteilt, dass diese Datei nicht indexiert (nicht über die Suche gefunden) werden soll.
# noindex robots.txt
<ifmodule mod_headers.c>
<files "robots\.txt">
Header set X-Robots-Tag "noindex"
</files>
</ifmodule>
Eine Überprüfung durch einen Aufruf meiner robots.txt unter https://www.redirect301.de/robots.txt und dem Anzeigenlassen des HTTP Response Headers mit Hilfe der Webdeveloper Toolbar zeigt den Eintrag X-Robots-Tag: noindex an.
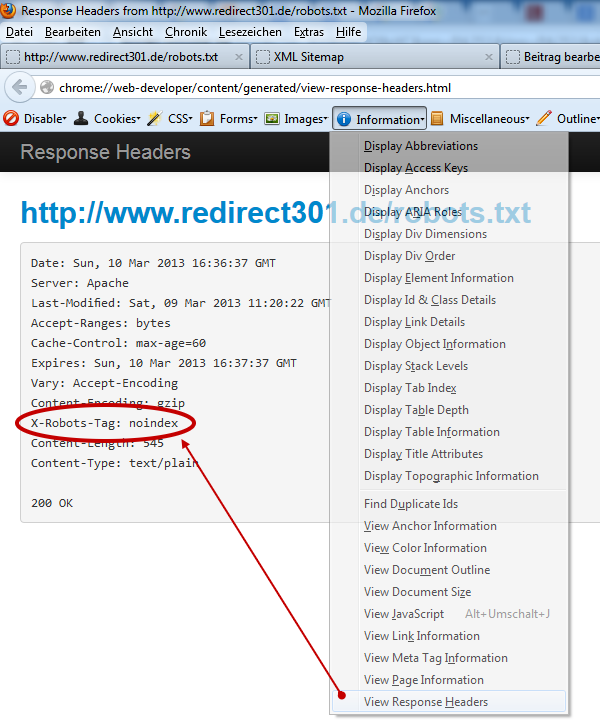
Noindex Response Header (Webdeveloper Toolbar)
Mehrere Dateien per X-Robots-Tag vom Suchmaschinen-Index ausschließen
Dieses Code-Beispiel für die htaccess-Datei stellt sicher, dass die Dateien robots.txt, sitemap.xml und readme.txt nicht im Suchindex bei Google & Co. auftauchen.
# noindex robots.txt, sitemap.xml, readme.txt
<ifmodule mod_headers.c>
<files "robots\.txt|sitemap\.xml|readme\.txt">
Header set X-Robots-Tag "noindex"
</files>
</ifmodule>
Bilder auf „noindex“ setzen
Wer nicht möchte, dass Bilder in den Suchmaschinen aufgenommen werden, kann die verwendeten Bildtypen mit den folgenden Anweisungen auf „noindex“ setzen. Dieses Beispiel sendet den X-Robots-Tag „noindex“ für Bilder mit den Dateiendungen gif, jpg, jpeg, png, bmp und tif bzw. tiff. Mit Hilfe von regulären Ausdrücken können Jokerzeichen wie das Fragezeichen oder auch das Sternchen beliebige Zeichen ersetzen.
# noindex images
<ifmodule mod_headers.c>
<files ~ "\.(gif|jp?g|png|bmp|tif?)">
Header set X-Robots-Tag "noindex"
</files>
</ifmodule>
Noindex für Backup-Dateien und/ oder Dokumente
In diesem Beispiel werden möglicherweise in der DocumentRoot abgelegte Backup-Dateien und nicht für eine Indexierung bestimmte Dateitypen für eine Anzeige innerhalb der Suchergebnisseiten ausgeschlossen Zusätzlich wird mit „nofollow“ ein Folgen eventueller Links innerhalb dieser Dateien blockiert. Prinzipiell haben diese Dateien dort nichts zu suchen, aber … sucht selbst.
# noindex robots.txt
<ifmodule mod_headers.c>
<files ~ "\.(bak|old|~?|doc|xls|mysql)$">
Header set X-Robots-Tag "noindex, nofollow"
</files>
</ifmodule>
Tabelle mit Anweisungen für die Indexierungs-Steuerung
Neben den bekannten und oft eingesetzten noindex und nofollow existieren, zumindest bei Google, noch einige weitere Anweisungen zur Indexierungs-Steuerung von Seiten und Dokumenten im Internet. Die folgende Tabelle enthält die derzeit möglichen Direktiven.
| Anweisung | Bedeutung |
|---|---|
| all | ist die Standard-Anweisung und stellt keinerlei Beschränkung in der Indexierung dar; auf diese Regel kann somit verzichtet werden |
| noindex | Inhalt des Dokuments (Webseite, Datei) erscheint nicht im Suchmaschinen-Index |
| nofollow | Links im Dokument (Webseite, Datei) werden nicht von der Suchmaschine verfolgt |
| none | Entspricht den Direktiven „noindex, nofollow“ |
| noarchive | Inhalte werden nicht als Cache-Variante angezeigt |
| nosnippet | es wird zum Dokument kein Snippet auf der Suchergebnisseite angezeigt |
| noodp | es werden nicht eventuell vorhandene Metadaten ODP auf den Suchergebnisseiten angezeigt |
| notranslate | es wird auf die Übersetzungsmöglichkeit des Dokuments durch „Diese Seite übersetzen“ bei Google verzichtet |
| noimageindex | Bilder dieser Seite werden nicht indexiert |
| unavailable_after: [RFC-850 date/time] | nach dem angegebenen Datum soll die Seite nicht mehr in den SERPs erscheinen; Bsp. RFC-850: Sunday, 13-Mar-13 16:00:00 UTC |
(Quelle: google.com)
Mehrere Indexierungs-Direktiven miteinander verknüpfen
Alle Direktiven können sinnvoll miteinander verknüpft werden. Im folgenden Beispiel werden somit alle PDF- und Word-Dokumente zwar indexiert, aber eventuell vorhandenen Links innerhalb der Dokumente wird nicht gefolgt. Außerdem werden Bilder innerhalb dieser Dateien nicht in den Suchmaschinen-Index aufgenommen und auch keine Cache-Versionen auf den Suchergebnisseiten angeboten.
# example pdf, doc
<ifmodule mod_headers.c>
<files ~ "\.(pdf|doc)$">
Header append X-Robots-Tag "index, nofollow, noimageindex, noarchive"
</files>
</ifmodule>
Wie lässt sich der HTTP-Header anzeigen/ überprüfen?
Es gibt eine ganze Reihe Browser-Erweiterungen für Chrome und Firefox, mit denen sich direkt im Browser der HTTP-Header anzeigen lässt.
Zudem existieren diverse Online-Tools im Netz, bei denen sich direkt auf der Website eine HTTP-Header Abfrage starten lässt. web-sniffer.net oder headers.cloxy.net sind sicherlich 2 gute Anlaufstellen, um mal schnell die Kopfzeilen zu checken.
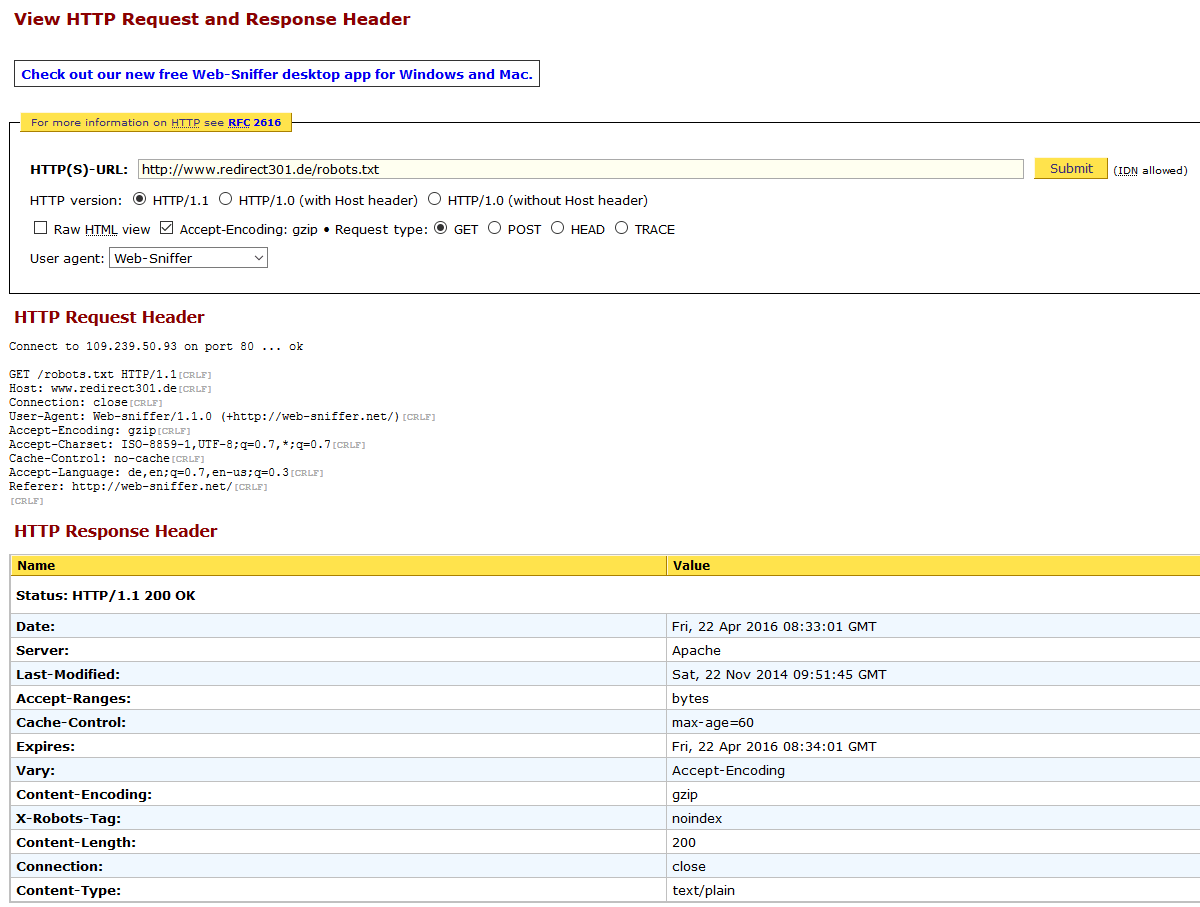
Web-sniffer.net
Unter Linux ist vielleicht die Kommandozeile der schnellste Weg. Mit dem Aufruf:
lynx -dump qj-hqead https://www.redirect301.de/robots.txt
gibt es die Informationen umgehend auf der Standardausgabe.
HTTP/1.1 200 OK Date: Sun, 13 Mrz 2013 08:40:21 GMT Server: Apache Last-Modified: Fri, 12 Nov 2013 09:51:45 GMT Accept-Ranges: bytes Content-Length: 422 Cache-Control: max-age=60 Expires: Sun, 10 Mrz 2013 08:41:21 GMT Vary: Accept-Encoding X-Robots-Tag: noindex Connection: close Content-Type: text/plain
Auf jeden Fall daran denken, die Datei(en) auf den gewünschten X-Robots-Tag hin zu überprüfen und ein Tipp für alle mit einer externen IT: Regelmäßig einen Blick auf diesen Status haben! Hierbei helfen Tools wie Screaming Frog oder Onpage.org, um das nicht regelmäßig händisch durchführen zu müssen.

Kommentar hinterlassen zu "Noindex: robots.txt & sitemap.xml"